Информационная безопасность
Обфускация управления
Обфускация такого вида осуществляет запутывание потока управления, то есть последовательности выполнения программного кода.
Большинство ее реализаций основывается на использовании непрозрачных предикат, в качестве, которых выступают, последовательности операций, результат работы которых сложно определить (само понятие "предикат" выражает свойство одного объекта (аргумента), или отношения между несколькими объектами).
Определение. Предикат "Р" считается непрозрачным предикатом, если его результат известен только в процессе обфускации, то есть после осуществления процесса обфускации, определение значения такого предиката, становится трудным.
Обозначим непрозрачный предикат, возвращающий всегда значение TRUE как "Р(t)", а возвращающий значение FALSE, как "Р(f)", тогда непрозрачный предикат, который может возвратить любое из этих двух значений (то есть или TRUE, или FALSE, что нам неизвестно) как "Р(t,f)". Эти обозначения, будут использоваться дальше в контексте описания обфускации управления. Непрозрачные предикаты могут быть:
- локальными - вычисления содержаться внутри одиночного выражения (условия), например (запись "(f)" после условия проверки, указывает, что это предикат типа "P(f)"):
if (($a * $b) == (101-303))(f) {...}
- глобальными - вычисления содержаться внутри одной процедуры (функции), например (PERL): sub func { $ab=$a*$b ; ... $val=101-303 ; ... if ($ab == $val)(f) {...} }
- межпроцедурными - вычисления содержаться внутри различных процедур (функций): ... $ab ... ; ... $val ... ; sub func1 { $ab=$a*$b; ... } sub func2 { $val=101-303; ... } ... if ($ab == $val)(f) {...} ...
Рассмотрим простые примеры трансформации фрагмента кода программы с помощью непрозрачных предикатов,
На рисунке 0110(1) один блок программы "(A)", разбит (трансформирован) на несколько независимых блоков "(A1; A2)", которые соединены по средствам непрозрачного предиката возвращающего всегда значение TRUE "Р(t)".
В результате трансформации такого рода возникает представление того, что блок "А2" выполняется не всегда, поэтому для того чтобы определить условия выполнения блока "А2", злоумышленнику прежде придется узнать значение, которое возвращает используемый непрозрачный предикат "Р(t)".
На рисунке 0110(2) помимо блока "А2", используется еще один блок "А2" над которым был произведен процесс обфускации (обозначим его как "А2`"), то есть эти два блока ("А2" и "А2`") имеют различный код, но выполняют одинаковые функции, следовательно, можно утверждать, что "А2 = А2`", и поэтому неважно какой из этих блоков будет выполнен в процессе работы программы, из этого следует, что для соединения блока "А1" с "А2" и "А2`" эффективно будет использовать непрозрачный предикат, который может возвратить любое из значений, а именно TRUE или FALSE "Р(t,f)".
И на рисунке 0110(3) используется новый блок "А3", который содержит произвольный набор, каких либо операций (недостижимый код), это может позволить сбить с толку злоумышленника, так как сами блоки "А1" и "А2" соединены по средствам непрозрачного предиката возвращающего всегда значение FALSE "Р(f)".
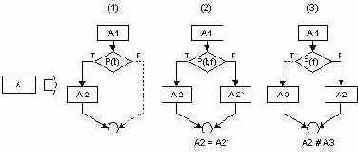
Рисунок 0110. Использование простых непрозрачных предикатов
Эффективность обфускации управления в основном зависит от используемых непрозрачных предикат, это вынуждает создавать как можно сложные для изучения, и простые, гибкие в использовании непрозрачные предикаты, но в равной степени также не маловажную роль имеет время их выполнения, а также количество выполняемых операций, помимо всего этого предикат не сильно должен отличаться от тех функций, которые выполняет сама программа, и не должен содержать чрезмерное количество вычислений, в противном же случае злоумышленник, сможет сразу его обнаружить. Так как часто для деобфускации используют технологию статического анализа, а одним из ее недостатков является сложность (трудоемкость) статического анализа структур указателей, то обычно в процессе обфускации управления используют устойчивые непрозрачные предикаты, которые позволяют использовать недостатки технологии статического анализа.
Основная идея устойчивых непрозрачных предикатов состоит в том, что в программу, в процессе обфускации добавляется код, который создает набор динамических структур, а также глобальных указателей, которые будут ссылаться на различные элементы внутри этих структур. Помимо этого, данный код должен иногда обновлять эти структуры (добавлять новые элементы в них, объединять или разделять некоторые их них, изменять значения глобальных указателей, и т.д.), но таким образом, чтобы при этом были сохранены некоторые условия, например "указатель p и q никогда не будут указывать на один и тот же элемент" или "указатель p может ссылаться (указывать) на указатель q" и т.д. Эти условия в последствии позволяют создавать требуемые непрозрачные предикаты.
На рисунке 0111, представлен пример использования устойчивых непрозрачных предикатов. На начальном этапе работы программы, код который был в нее добавлен в процессе обфускации, создает динамическую структуру "struct", и два глобальных указателя "p, q" которые указывают на произвольные элементы, внутри этой структуры, "Рисунок 0111(1)", поэтому для этих указателей справедливо, что условие:
if (p==q) { ... }
соответствует предикату "Р(t,f)".
На следующих этапах процедура "Insert()" добавляет в эту структуру новый элемент, "Рисунок 0111(2)", и изменяет значение указателя "q", "Рисунок 0111(3)", при этом условие для указателей "p, q" продолжает оставаться неизменным.
После выполнения следующей процедуры, происходит разделение динамической структуры, на две отдельные, таким образом, что указатели "p, q" теперь указывают на элементы, которые находятся в различных структурах, "Рисунок 0111(4)", и поэтому для них теперь справедливо иное условие:
if (p==q) { ... }
Которое соответствует предикату "Р(f)".
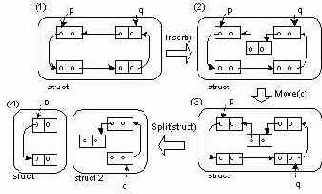
Рисунок 0111. Использование устойчивых непрозрачных предикатов
Таких манипуляций с указателями, и структурами, можно делать очень много, они могут быть добавлены в разные участки программы, и их можно усложнить, а также добавить какие-то уникальные процедуры для работы со структурами.
При этом существующие алгоритмы статического анализа становятся не эффективны.
Методы позволяющие осуществить обфускацию управления, классифицируются на три основных группы:
Обфускация вычислительная. Изменение касающиеся главной структуры потока управления. К ним можно отнести:- расширения условий циклов. Для этого обычно используют непрозрачные предикаты, таким образом, чтобы они не коим образом не влияли на количество выполнений циклического кода. Например, фрагмент кода (PERL):
$i = 1 ; while ($i < 101) { ... $i++ ; }
после расширения условия цикла, станет:
$i = 1 ; $j = 100 ; while (($i < 101) && ($j * $j * ($j + 1) * ($j + 1)%4 == 0)(t)) { ... $i++ ; $j = $j * $i + 3 ; }
- добавления недостижимого кода, (который не будет выполняться в процессе работы программы) (рисунок 0110(3)).
- устранение библиотечных вызовов. Большинство программ, используют функции, которые определены в стандартных библиотеках исходного языка, на котором писалась программа (например, в Си это библиотека "libc"), работа таких функции хорошо документирована и часто известна злоумышленникам, следовательно, их присутствие в коде программы, может помочь в процессе ее реверсивной инженерии. Поэтому имена функций из стандартных библиотек, также желательно придать обфускации, т.е. изменить на наиболее бессмысленные, которые потом будут фигурировать в коде защищаемой программы. Один из способов решения такой проблемы, заключается в использовании в программе собственных версии стандартных библиотек (которые получаются в результате переименовывания всех функций в оригинальной стандартной библиотеке), это не изменит существенно время выполнения программы. Но для того, чтобы такая программа была переносимой, и могла использоваться многими пользователями, ее нужно будет поставлять вместе с измененной версией стандартной библиотеки, что значительно увеличит размер программы. Поэтому такой способ решения проблемы неэффективный. При осуществлении такой обфускации следует в первую очередь основываться на особенностях стандартной библиотеки исходного языка (то, как в ней взаимосвязаны имена функций с ихними кодами и т.д.).
- добавление избыточных операций (мертвого кода) в те участки программного кода, которые наиболее трудные (изначально) для изучения. Часто избыточные операции, используются для расширения арифметических выражений (например, в непрозрачных предикатах), находящихся в коде программы, таким образом, запись:
$X = $X + $Y ;
может быть представлена:
$X = $X + $Y * $p - $r ;
где "$r == 0", "$p == 1".
- параллелизирование кода, заключается в разделении кода на отдельные независимые участки, которые во время работы программы будут выполняться параллельно (т.е. одновременно), такая обфускация также может заключаться в импровизации параллелизирования кода программы, для это создается так называемый макет процесса, который на самом деле не будет выполнять не каких полезных операций.
Обфускация соединения. Объединение или разделение определенных фрагментов кода программы, для того чтобы убрать логические связи между ними. Ниже приведены основные методы, позволяющие осуществить такую обфускацию:- встраивание функций, осуществляется путем встраивания кода функции, в места ее вызова (если ее код будет встроен во все места ее вызова, тогда саму функцию можно убрать из кода программы).
- извлечение функций, является обратным действием, по отношению к встраиванию функций. Осуществляется в результате объединения некоторой группы взаимосвязанных операторов в коде исходной программы в отдельную функцию (при необходимости для этой функции можно определить некоторые аргументы), которой потом замещают эти группы операторов. Но следует учесть, что такое преобразование может быть снято компилятором в процессе компиляции кода программы.
- чередование, объединение фрагментов кода программы (функций например), выполняющих различные операции, воедино (в одну функцию, при этом в такую функцию, следует добавить объект, в зависимости от значения которого, будет выполняться код одной из объединенных функций). Например, после объединения функций (PERL):
... func1() ; ... func2() ; ...
sub func1 { # код func1 } sub func2 { # код func2 } ... можно получить:
... $V = $V*31337 / 13 ; # $V == 0 ... func12() ; ... $V += 7 ; # $V == 7 ... func12() ; ... sub func12 { if ($V) { # код func2 } else { # код func1 } } ...
- клонирование, данный метод позволяет усложнить анализ контекста использования функций, и объектов используемых в коде исходной программы. Процесс клонирования функций состоит в выделении определенной функции "F", часто используемой в коде программы, после чего над кодом этой функции осуществляется трансформация, и создается ее клон "F`", который также будет добавлен в код исходной программы, при этом часть вызовов функции "F" в коде исходной программы, будет замещена на вызов функции "F`". В результате этого у злоумышленника создастся представление о том, что функции "F", и "F`" различны. Клонирование объектов осуществляется аналогичным способом.
- трансформация циклов. Циклы встречаются в коде различных программ, и их также можно придать трансформации. Блокирование циклов, заключается в добавлении вложенных циклов в существующие, в результате работа существующих циклов будет заблокирована, на какой-то диапазон значений. Например, имея 2 цикла (PERL):
for ($i = 1 ; $i =< n ; $i++) { for ($ii = 1 ; $ii =< n ; $ii++) { $a[$i, $ii] = $b[$i, $ii] ; } } можно создать 4 цикла (функция "min" должна возвращать минимальное значение, одного из своих аргументов):
for ($I = 1 ; $I =< n ; $I += 64) { for ($II = 1 ; $II =< n ; $II += 64) { # первые два цикла будут заблокированы до тех пор, # пока не будут перебраны все значения "n" или # пока не будут перебраны все значения # из промежутка ($I,63) и ($II,63) for ($i = I ; $i =< min($I + 63, n) ; $I += 64) { for ($ii = II ; $ii =< min($II + 63, n) ; $ii++) { $a[$i, $ii] = $b[$i, $ii] ; } } } }
- Развертка циклов, повторение тела цикла один или более раз (если количество выполняемых циклов известно в процессе осуществления обфускации (например, равно "N"), то цикл, может быть, развернут полностью, в результате повторения его тела в коде N раз):
for ($i = 1 ; $i =< n - 1 ; $i++) #PERL { # тело цикла }
после простой развертки:
for ($i = 1 ; $i < n - 1 ; $i++) { # тело цикла } # тело цикла
- Разделение циклов, цикл состоящий из более чем одной независимой операции можно разбить на несколько циклов (которые должны выполняться одинаковое количество раз), предварительно разбив на несколько частей, его тело. Например, следующий цикл (PERL):
for ($i = 1 ; $i < n ; $i++) { $a[$i] += $c ; $x[$i+$i]=$d+$x[$i+1] * $a[$i] ; }
после разделения, может быть представлен: for ($i = 1 ; $i < n ; $i++) { $a[$i] += $c ; } for ($i = 1 ; $i < n ; $i++) { $x[$i+$i]=$d+$x[$i+1] * $a[$i] ; }
Желательно осуществлять над исходным циклом последовательно все вышеперечисленные трансформации циклов, это позволит усложнить его статический анализ.
Обфускация последовательности. Заключается в переупорядочивании блоков (инструкций переходов), циклов, выражений.
Содержание раздела

- расширения условий циклов. Для этого обычно используют непрозрачные предикаты, таким образом, чтобы они не коим образом не влияли на количество выполнений циклического кода. Например, фрагмент кода (PERL):
